
Business Requirement
Sometimes we need to fetch huge data from a Cloud Environment and BI Report fails stating Report Data Size Exceeds Maximum Limit

In such cases, we might make use of the concept of using multithreading. What this essentially does is that it breaks the entire program into smaller chunks such that if you have say 10K records to process you may break them into smaller units say of 1K each and submit the program 10 times. Each one of the program runs on its own without interfering with the other and you get the desired data (the only drawback being they are in different files and maybe a merge operation is required). But having said so it still serves the purpose and at-least one is able to get the data from the system instead of the first approach when you hit a dead-end.
I will try to explain this with the help of a worked-out example.
Worked Out Example
In the diagram above we saw that the Report failed stating “ Report Data Size exceeds the maximum limit. Stopped processing”
In order to overcome such a problem we need to break the entire data into smaller chunks.This can be done by first of all identifying the Total No Of Records which is fetched by the report.
The general syntax of determine this is by following the below SQL syntax
|
SQL Syntax to Find Record Count |
|
SELECT TAB1.COUNT(UNIQUE_IDENTIFIER) as “RECORDCOUNT” FROM ( SELECT UNIQUE_IDENTIFIER, COLUMN2, ……, ……., COLUMNN FROM TABLE1, …….., …………, TABLEN WHERE TABLE1.COLUMN1 = TABLE2.COLUMN2 AND …………………………………. AND …………………………………….. ) TAB1 |
For this example, we have used the delivered report “Worker Report”. The report location is
Shared Folders->Human Capital Management->Data Exchange -> Worker Report
For this particular cloud environment I applied the same logic and could figure out that the total no of records are 66511
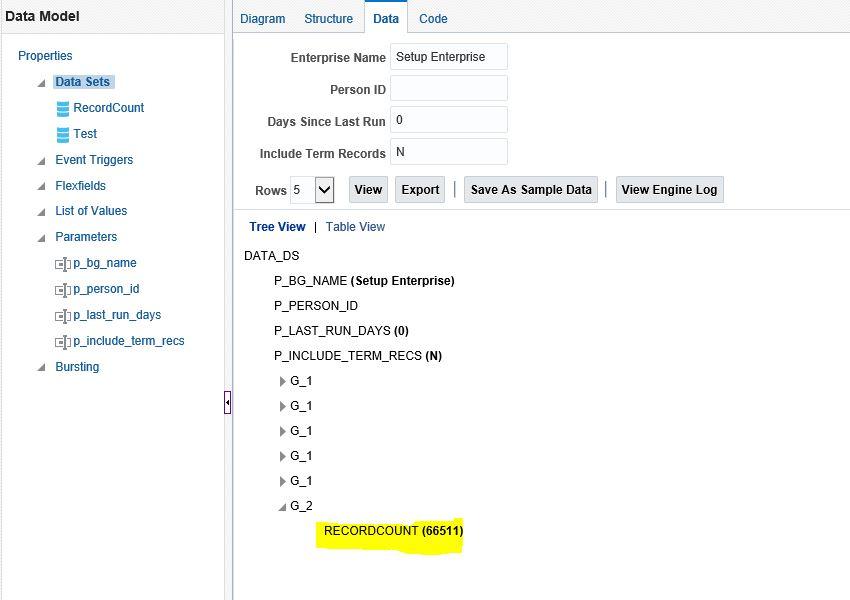
Next we need to decide the chunk size for each run. In my case I decided to have the below bifurcation
|
Batch Sequence |
Record Sequence |
|
Batch1 |
1-10000 |
|
Batch2 |
10001-20000 |
|
Batch3 |
20001-30000 |
|
Batch4 |
30001-40000 |
|
Batch5 |
40001-50000 |
|
Batch6 |
50001-60000 |
|
Batch7 |
60001-66511 |
Now although we have decided the no of batches and the chunk size one important thing is still left and that is assigning RECORD_SEQ to each data record fetched by the query.
In order to do so we would make use of the ROWNUM property of the SQL.
Also we would need to use two additional parameters namely START_SEQ and END_SEQ to ensure the correct records are picked in correct batch.

The lines highlighted in RED fonts in the ModifiedSQL.sql is the section newly added to the original sql.
Executing Report
Now as the new report is ready we will try to execute the same and find the results.

Inference/Summary
So now we have seen how we can use parallel processing technique to overcome data size issue while fetching Data using a SQL Data Model Based BI Report in a Cloud Environment.
While this example was used for a specific report the same method can be applied to any other report (both seeded as well as custom) and hopefully it will deliver desired results. This technique should work not only for HCM but for other modules too be it Financial, SCM, PPM etc. In a nutshell, anywhere where you use a BI SQL to fetch data this trick can be applied.
Do try at your end and feel free to let-us know your observations.
That’s all from my side have a nice day ahead!


Comments
Thanks a lot.
My web page: w88: https://w88yesvn.com/
RSS feed for comments to this post