INTRODUCTION
This topic explains about aggregate persistence wizard that is used for creating and modelling aggregate tables. It further illustrates the concepts of fragmentation or partitioning which are the most powerful features of OBIEE and method of creating and using variables.
-
Aggregate Persistence Wizard
There is a wizard that creates parent-child relationship and tells the BI Server that which is the parent and child. The wizard will create aggregate tables and model it.

-
Open the wizard
-
Select Tools->Utilities->Aggregate Persistence to open the wizard and click Execute button.
-
Specify a file and location where the output script should be saved.
-
Specify Business Model and Measures
-
In the top pane of the Select Business Measures screen, select the Business Model. When there are multiple models, only one Business model can be selected.
-
In the bottom pane, select the fact table. When there are multiple fact tables, only one fact table can be selected.
-
Expand the fact table and select desired measures.
-
Select Dimension Levels
Select corresponding aggregate dimensions and levels.
-
Select Connection Pool
-
In the top pane of the Select Connection Pool screen, select the repository database object.
-
In the expand pane, expand the database object and select the desired schema. In this example, there is only one schema SUPPLIER2.
-
In the third pane, select the connection pool. In this example, there is only one, SUPPLIER CP.
-
In the Aggregate table in name field, select the default name or create a new name for the aggregate table. In this example, the default name is ag_Fact_Sales.
Note: The parameters provided here are for output, which could be to a different database than where the detail table reside.
-
Review Aggregate Definition
-
-
View Aggregate Script


-
Verify script is created
Navigate to the directory where the file was saved and verify that the script was created as expected.
-
Run script using nqcmd
Use the nqcmd utility to run the aggregate persistence script.

-
Verify Aggregates in the physical layer
Verify that the aggregates are created in the physical layer of the repository as desired.
-
Verify Aggregates in BMM Layer
Verify that the aggregates are created in the BMM layer of the repository as expected.
-
Verify in Database
Verify that the aggregate tables are created in the database.

-
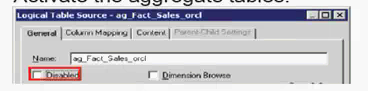
Activate the aggregate table
-
Run an analysis
Check the log and verify that the aggregate tables are accessed as expected.
-
Troubleshooting Aggregate Navigation
If aggregate navigation is not working or not creating the correct aggregate table, the cause might be one of the following:
-
Aggregate content is not specified correctly for one or more sources.
-
Aggregate dimension sources are not physically joined to aggregate fact tables at the same level.
-
A dimensional source does not exist at the same level as the fact table source.
-
Aggregate dimension sources do not contain a column that maps to the primary key of the dimension hierarchy level.
-
The number of elements is specified correctly for dimension hierarchy levels.
Best Practices
-
Using aggregates comes with a price
-
Additional time is required to build and load these tables.
-
Additional storage is necessary.
-
Build only the aggregates you need
-
Look at query patterns and build aggregates to speed up common queries that require summarized results.
-
Ensure that enough data is combined to offset the cost of building aggregates.
-
Monitor and adjust to account for changing query patterns.
-
Partition and Fragments
-
Business Challenge
Data is often partitioned into multiple physical sources for a single logical table in a business model
When a logical table source does not contain the entire set of data at a given level, you need to specify the portion or fragment of the set that it contains.
For example, there are situations in which data may be fragmented or partitioned. When individual sources at given level contain information for a portion or fragment of the domain, an application needs to know the content of the sources to pick the appropriate source for the query.
This should not have impact on the end-user experience. The way of data access should be completely transparent to the end-user.
-
Business Solution
When there are multiple sources, the metadata can be built so that Oracle BI Server handles navigation to the appropriate source. Oracle BI Server do seamlessly access and process data from multiple sources efficiently to satisfy user requests.
Partitioning can be done by building smaller separate databases or by splitting larger selected elements into smaller ones (For example, splitting one larger table into many smaller tables). When a user requests data, it may be necessary to consolidate data from different partitions to complete the request.
-
Complex Partitioning
Partitioning strategies can be mixed. For example, data can be partitioned by level and value so that at any given intersection of levels, multiple aggregate tables may exist. Moreover, at any given intersection of levels, not all values might be stored.
For example, at a Brand, Month, and Market aggregate level, just the important brands might be stored. Certain queries at this level can use the aggregate tables; other queries, with different constraints, have to use more detailed tables.
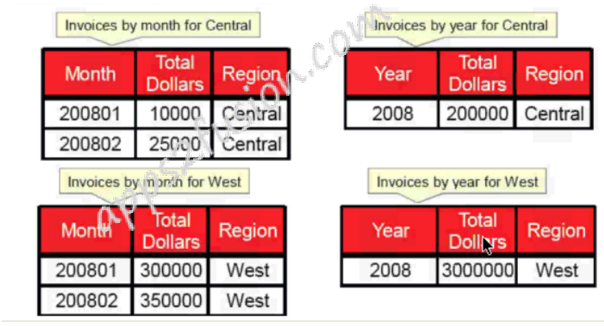
Example
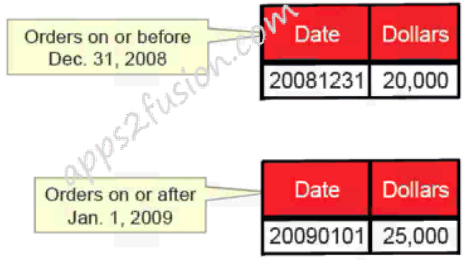
Replace the current, single source for order data with two value-based partitions.
-
Specify Fragmentation Content
When a LTS does not contain the entire set of data at a given level, you need to specify the portion, or fragment, of the set that it contains. Describe the content in terms of logical columns, using the “Fragmentation content” edit box on the Content tab of LTS window. Click the button next to the “Fragmentation content” box to open the Expression Builder to build the expression.
This is similar to the steps used to define aggregates. For aggregates, you specified the content by using the level indicator. Here you use an expression to serve the same purpose – to identify what data the source contains. In this example, the Facts-Historical table contains data for orders on or before December 31, 2008. In a request for order data, this source may need to be combined with data from other sources at this level. In this example, that would be the Facts-Recent table, which contains the remaining order data.
-
Partitioning by Level
Data can also be partitioned by level. This occurs when the same facts are stored in separate tables at different levels of aggregation. The use of aggregate tables is a common practice in data warehouse design because it is a very effective tool for improving query performance.
However, the number of aggregate tables in a data warehouse can be very large. As such, data warehouse designer prefer to follow an incremental approach to create aggregations. They look for the best performance, creating the aggregate tables that are going to be used most frequently and that offer the most data compression.

-
Partitioning by Fact
Data can be stored in such a way that different facts are in different tables. For example, companies usually store sales quotas in tables separate from the actual sales history. Inventory data is also commonly found stored in a database separate from sales history.
This is sometimes referred to as vertical partitioning because a theoretical all-encompassing fact table can be thought to be sliced “vertically”, with different columns going to different fact tables.
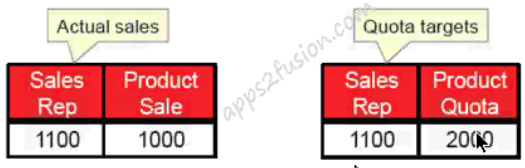
-
Partitioning by Value
Data can be partitioned into separate tables according to the values of the data.
Examples:
East region sales data may be in a different table from West region sales data.
Inventory data may be in separate tables segregated by warehouse.
The data for the current year may not be in the same table as the data for prior years, or data could be separated by month, so that last three years of data are in 36 separate tables.
This type of partitioning creates complexity in the query environment. One of the important benefits of Oracle BI Server is that it can do this type of navigation and consolidation automatically, preserving a simple logical model of the data with which users interact.
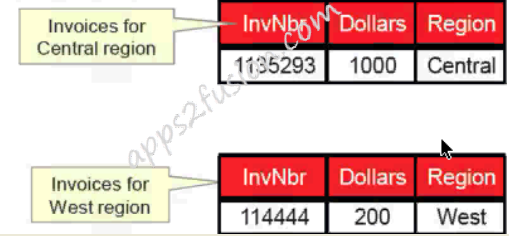
-
Variables
-
Contain values in memory that are used by Oracle BI server during its processing
-
Variables are created and managed using the Variable Manager feature in the Administrator tool.
-
The variables are categorized into two types namely session variables and Repository variables.
-
Variable Manager
It is a utility in the Administration tool that is used to define variables.
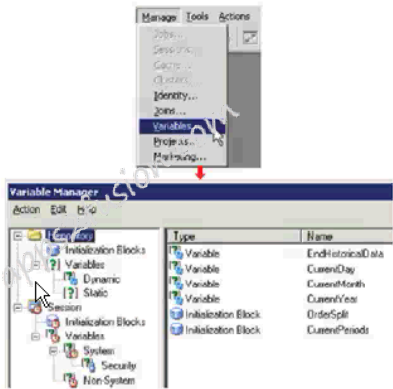
-
Types of Variables
There are two classes of variables namely repository variable and session variable.
-
Repository Variable
A repository variable has a single value at any point in time. There are two types of repository variables: static and dynamic. Repository variables are represented by a question-mark icon (?).
-
It persists from the time Oracle BI Server is started until it is shut down.
-
It can be used instead of literals or constants in the Expression Builder in the Admin tool.
-
Oracle BI Server substitutes the value of the repository variable for the variable itself in the metadata.
-
Dynamic Repository Variable
You initialize dynamic repository variable in the same way as static variables, but the values are refreshed by data returned from queries. When defining a dynamic repository variable, you create an initialization block or use a pre-existing one that contains a SQL query. You also setup a schedule that Oracle BI Server follows to execute the query and refresh the value of the variable periodically.
When the value of the dynamic repository variable changes, all cache entries associated with the business model that reference the value of that variable are purged automatically. Each query can refresh several variables- one variable for each column in the query. In this example, the query returns three columns (YYYYMMDD, MONTHCODE, YEAR) that refresh the variables: CurrentDay, CurrentMonth and CurrentYear.
A common use of the variables is to set column filters in analyses. For example, to filter the column on the value of the dynamic repository variable CurrentMonth, set the column filter to the variable CurrentMonth.
-
Session Variables
Session variables are created and assigned a value when each user logs on. There are two types of session variables namely system and non-system. System and non-System variables are represented by a question-mark icon (?).
Initialization blocks are used to initialize dynamic repository variables, system session variables, and non-system session variables. The icon for an initialization block is a cube labelled with letter i.